
随笔分类
Index Concurrent Control
我们的系统中存在着大量的线程,这样做的目的是来 最大化并行能力,或者是最大程度上减少我们想要执行查询时的延迟
因此,当我们想通过多线程来更新和访问我们的数据结构,我们该如何保证线程安全?
目前市场上主流的数据库都支持多线程,但还是存在些例外:
- Redis:基于单线程的内存数据库
- VoltDB:虽然是多线程的数据库,但其以某种方式将数据库进行分割,即每个 B+Tree只能由一条单个线程来进行访问
实际上,我们保护我们的数据结构的方式是通过一种 并发协议 或 并发方案来解决的,这也是 DBMS用来保证数据结构正确性的一种方式:即 强制所有访问数据结构的线程都使用某种协议或者是某种方式
这里所说的数据结构针对于共享对象,包括但不仅限于:tuple、index、page table以及 buffer pool等
在并发控制中,我们所关心的两种正确性类型:
-
逻辑正确性
高级层面的东西
如果我在访问该数据结构时,我希望看到的值是自己想要的
对于逻辑正确性,当我们在讨论
事务和并发结构,我们会对此更为关心 -
物理正确性
这也是我们主要去关心的
如:我们该如何去保护数据结构的内部表示呢?
该如何维护指针以及指向其它 page的引用,还有 key和 value呢?
我们该如何去确保线程读写数据时,该数据结构的正确性?
Lock VS Latch

这里其实在之前已经讲过了,这里就大致做些许总结吧:
-
Locks
高级层面的东西
通过 Lock来去保护数据库中
逻辑内容事务执行期间会去持有 Locks,因为事务可能会被其它线程破坏,因为这些线程可以来更新同一个 tuple (如果没有锁的话,就出大事了!)
需要其能够去 支持 Roll Back
-
Latchs
低级、底层层面的东西
我们主要来关心的是
用来保护数据结构或对象的物理完整性的 latch,latch会去保护数据库系统的关键部分在 os世界中,会去将 latch叫做 lock 或者 mutex
在 DB世界中,我们将其叫做 latch,因为我们需要将其区分于 lock
latch可以保护内部数据结构免受其它线程对该数据结构或对象同一时刻进行读写所带来的问题so,我们只会在一小段时间内持有 latch,我们只会在对关键部分进行所需操作时去持有这个 latch
这里,我们不需要能够去回滚任何修改
- 因为我们所尝试要进行的操作,本质上来讲是原子性操作
当我们成功获取 latch后,我们就能够去做任何想做的修改了
接着,当我释放了这个 latch后,那么这些操作就被认为是完成了
so,这样就执行了所有的修改
Latch
Mode
对于 latch,只有两种 modes:
-
Read Mode
允许同一时间有多个线程去读取数据结构
-
Write Mode
独占式的 latch
Implementation
实现,这也是我们程序员所关注的
Blocking OS Mutex
使用 os提供的互斥锁,许多语言其实都内嵌了对其的支持
Example:std::mutex

实际上,我们应该 尽可能去避免去使用 os层面的东西,如 mutex
如线程去申请 os层面的 mutex,os知道你是被 mutex阻塞了,此时 os便会将线程放置在一个 等待队列 (联想 "管程",os有着自己的数据结构并进行管理者),等待被调度
如果是一个高竞争的系统,倘若所有东西都去使用 os层提供的 mutex,这就成问题了!
Test-And-Set Spin Latch
其实这就是 Java中的 CAS
这种做法非常高效,得源于 cpu的支持:存在着一条指令 cmpxchg,使用这条指令可以在一个内存地址上进行单次 CAS操作
// 通常会结合 "自旋"
boolean compareAndSwapXXX(int expect, int real, int res)实际上,这种做法在高并发的系统中可能会 燃尽我们的 cpu,os认为我们在做有用功 (os实际上并不知道我们具体地在做些什么),而 cpu却是在做无用功 (没有 cas成功)
作为数据库底层开发人员,可以在具体的实现时 进行调优
注意:我们在数据库系统中所做的可以比 os给我们提供的要来得更好,因为我们知道在那个上下文中,我们会去使用 latch
实际上,Linux中已经有了类似的实现了:Futex:Fast Userspace Mutex
它的工作方式是:会在 userspace中,也就是进程中的地址空间里面,会去占用一点内存地址,比如 1bit或者 1byte左右,会去通过这个内存地址来尝试进行一次 CAS操作,以来获取这个 latch
Futex的思想实际上就是 借助于一点内存地址来进行一次快速的 cas,以来获取 latch,如果没有拿到,那么就会去使用速度相对很慢的 os层面的 mutex
Read-Write Latch
以上的实现,会去持有具体类型的 latch
简单来讲,我们就是在基础的 latch原语之上构建出 spin latch或者 POSIX mutex这种东西
然后,我们会去 管理不同的队列来跟踪不同类型的 latch有哪些线程在等待获取,以此来避免 "饥饿等待":实际上,这是取决于我们具体想要使用的哪种策略
using
基于 latch,我们能够来做些什么事呢?
Hash Table Latching
由于线程 访问数据结构的方式有限,因此易于支持并发访问
- 所有的线程都像一个方向移动,一次只能访问一个页面 / 插槽
- 死锁是不可能出现的 (按照一定顺序进行读取,这不就是打破了 "环路条件" -> 死锁发生的四大必要条件之一)
当我们需要去调整 hash table的 size时,通常会在 header page上加一个全局 latch,这是为了我对 table的 resize调整结束前,避免其它线程对该 table进行读写操作
这里的 latch实现,区别在于 latch的粒度:(这两种方法间,计算和存储开销上进行了取舍)
-
Page Latches
在每个 page上,我们使用一个 read / write latch
如果使用 page latch,我们保存的 latch数量就比较少,一个 latch对应一个 page,但这会降低我们并行性
-
Slot Latches
使用细粒度更小的 Latch,即你可以在每个 slot上使用 latch
更高的并行性
保存更多的 latch
这样当我进行扫描时,获取 latch时要付出的代价会很高 (不仅占空间,而且也会占计算资源),因为我在扫描每个 slot时,都得去获取 latch
B+Tree latching
我们允许多个线程同时读取和更新一个 B树
这其实是一种 悲观的实现
为此,我们需要来 两个问题:
- 多个线程同一时间都试着修改同一个节点的数据,
- 有一个线程正在遍历 B+Tree,接着,在它下面,在它到达叶子节点前,另一个线程对 B+Tree进行了修改,这引起了节点间的拆分与合并,B+Tree中节点的位置可能会有所移动,我所查找的数据可能就并不在原来的位置上了 (因此,我们会认为数据已经不在 B+Tree中了,但实际上数据仍然存在)
甚至更糟糕的情况,我的指针指向了内存中的一个无效内存地址
为了解决这种问题,就去使用一种经典的技术:latch crabbing / coupling
latch crabbing
允许多个线程同时去访问 B+Tree
基本思想:在任何时候,当我们在一个节点中时,我们必须在该节点上挂一个 latch,不管是写模式 或 读模式的 latch都行,接着,在我们跳到我们的孩子节点之前,我们要拿到我们孩子节点上的 latch,即我们想要到达的下一个节点的 latch,然后,当我们落到那个孩子节点上时,我们要对它里面的内容进行测试,如果我们判断出来移动到该孩子节点是安全的话,那么,对我们来说将父节点上的 latch释放掉是 ok的
latch crabbing处理事情的方式,其实就像是螃蟹走路那样,走的时候,一条腿迈过另一条腿
定义 safe node:如果我们要进行一次修改,我们所在的节点无须进行拆分或合并操作,也不用去管它下面所发生的事情
-
节点未完全被填满当我们尝试着去插入东西时,我们要有足够的空间来容纳我们所要插入的 key
-
节点超过半满这样的话,我们删除一个 key时,就不需要去进行合并操作
so,基本上来讲,在 B+Tree中,当线程向下进行遍历时,会通过一个 stack来保存它一路上所持有的 latch
so,在某个时间点,当线程在一个安全的节点时,就可以释放掉该节点之前所有节点上的 latch
latch crabbing方式存在的问题?
当我们进行 insert、delete时,都必须要先去在 root上使用写锁,而 wirte latch是 exclusive,因此这也成为了并发的瓶颈
因此,有了一种针对其的优化方式:Better Latching Algorithm
Better Latching Algorithm
基本思想:采取 乐观态度,即大部分的线程不需要对叶子节点拆分或者合并操作,so,在向下访问 B+Tree时,所采用的的是 read latch,而不是 write latch,然后,我在 对叶子节点进行处理时,会去使用 write latch (如果只是 read ops,那么只会去获取 read latch),如果我判断出并不需要拆分的话,那么当我往下访问时,只需要拿到 read latch就行,并且可以来执行我想要的任意修改
如果我在进行拆分或者合并操作时犯错了,那么,我直接终止操作,并在根节点重启该操作,在向下遍历时获取 write latch
注:在到达 leaf node前,获取的都是 read latch,执行具体 insert、delete等操作时,才会去获取当前叶子节点的 write latch
这如同一场赌博,赢了血赚,输了需要重头再来...
如果操作失败,就必须要去重启该 ops吗?能不能在最近的 latch释放的 node处重启该操作,以来提高性能?
首先,需清楚一点:
read latch会去阻止任何人对这些节点进行写入和拆分操作 (因为这些 ops需要先去获取对应的 write latch)
write latch则是去阻止除了我之外的其它人对这些节点进行修改
当检测到叶子节点需要拆分,或者说是当前线程在当前叶子节点操作失败时,若是从最近的释放 latch的 node处重启操作,叶子节点的修改操作可能会将其影响 向上传递,而重启位置的节点其本身可能处于其它情况:满、半满、空,这可能会进行一个递归向上传递的过程,而这个过程是不安全的 (上面的节点可能已经在被操作了,如被其它线程上了 write latch,此时就是处于 "dead latch"状态了)
case:一条线程从上往下进行遍历,另一个线程则是在叶子节点上从左往右进行遍历,此时是有可能发生死锁现象的,该如何来进行处理?
其实是由三种处理方案的:
- 自旋等待获取
- 重启操作,这会导致
starvation的出现 - 直接争抢 latch
线程之间是不知晓彼此在做的事情的!
Leaf Node Scan
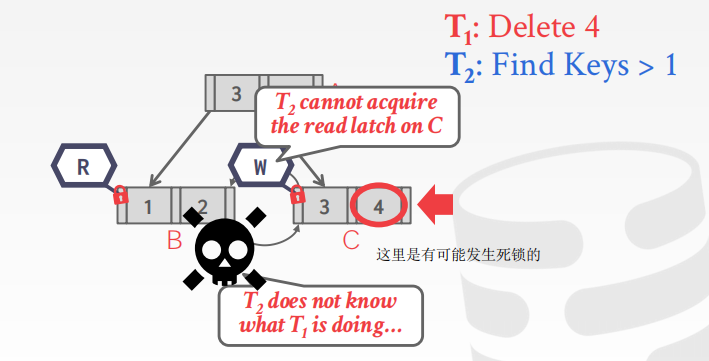
叶子节点处,实际上是有可能发生 dead lock
但是我们并不清楚其它线程所做的事情,因此,我们可以去等待一段时间,而不是过于保守,直接将操作终止
我们并不想去解释它们在尝试做的事情,我会直接说,我们没法拿到这些 latch,于是我们重新执行这些操作 (因为此处有一个死锁,我们需要 kill掉其中一个,打破死锁)
接着我们来讨论下在处理 overflow情况时可以使用的一种额外优化手段 (注:每当我们对叶子节点进行更新时,都伴随至少三次的 node updates,即对应着至少三次随机 IO):Delayed Parent Updates
Delayed Parent Updates
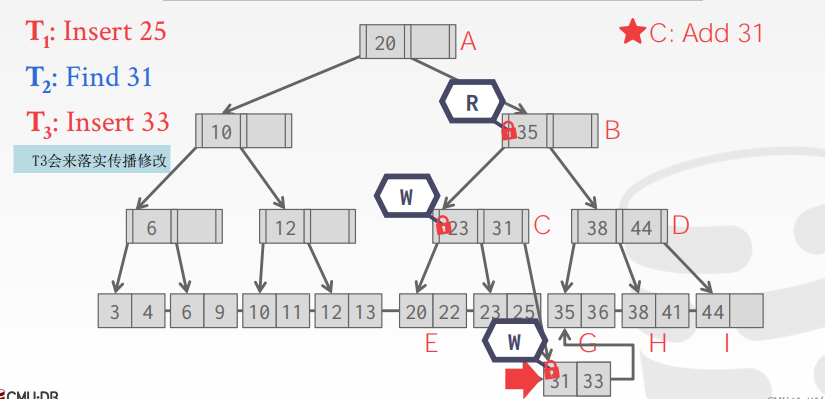
基本思想:延迟对父节点的更新操作,这样的话我们就不用去重头开始并拿着 write latch一路向下遍历了,只需要更新这棵树中全局信息表中一点点内容就可以了
当在某时刻,有人来遍历这棵树时,我们再去更新这个父节点 (即下一次有人修改此处的时候,会帮我 落实传播修改的)













